

6TOPS算力驱动30亿参数LLM,米尔RK3576部署端侧多模态多轮对话

2025-09-04

1084

来源:米尔电子
关键词:瑞芯微 RK3576、NPU(神经网络处理器)、端侧小语言模型(SLM)、多模态 LLM、边缘 AI 部署、开发板
当 GPT-4o 用毫秒级响应处理图文混合指令、Gemini-1.5-Pro 以百万 token 上下文 “消化” 长文档时,行业的目光正从云端算力竞赛转向一个更实际的命题:如何让智能 “落地”?—— 摆脱网络依赖、保护本地隐私、控制硬件成本,让设备真正具备 “看见并对话” 的离线智能,成为边缘 AI 突破的核心卡点。
2024 年,随着边缘 SoC 算力正式迈入 6 TOPS 门槛,瑞芯微 RK3576 给出了首个可量产的答案:一套完整的多模态交互对话解决方案。

如今,“端侧能否独立运行图文多轮对话” 已不再是技术疑问,而是工程实现问题。RK3576 通过硬件算力优化与软件栈协同,将视觉编码、语言推理、对话管理三大核心能力封装为可落地的工程方案,而本文将聚焦其多轮对话的部署全流程,拆解从模型加载到交互推理的每一个关键环节。

上一次我们详细讲解在RK3576上部署多模态模型的案例,这次将继续讲解多轮对话的部署流程。整体流程基于 rknn-llm 里的多轮对话案例[1]。

本文目录
本文目录 一、引言 1.1 什么是多轮对话? 1.2 多轮对话系统鸟瞰:三颗“核心”协同驱动 1.3 核心逻辑:多轮对话的处理流程 二、工程化落地:从源码到部署的全流程 2.1 依赖环境 2.2 一键编译 2.3 端侧部署步骤 三、效果展示:图文多轮问答 四、二次开发与拓展方向 五、结论与未来发展方向
一、引言
1.1 什么是多轮对话?
多轮对话(Multi-Turn Dialogue)是指用户与智能系统通过多轮交互逐步明确需求、解决问题的对话形式。这种交互依赖对话历史的上下文连贯性,要求系统能够动态理解用户意图、维护对话状态并生成符合语境的回应。
本质是动态语境下的交互推理,其核心在于通过多轮信息交换逐步明确用户需求。例如,用户可能先询问 “附近有餐厅吗?”,系统回应后用户补充 “要适合家庭聚餐的”,系统需结合历史对话调整推荐策略。
这种交互模式与单轮问答的区别在于:
1.2 多轮对话系统鸟瞰:三颗“核心”协同驱动
RK3576 多模态交互对话方案基于 RKLLM 的核心运作,依赖于图像视觉编码器、大语言模型与对话管家这三大模块的协同配合,三者各司其职、无缝衔接,共同构建起完整的多模态对话能力。
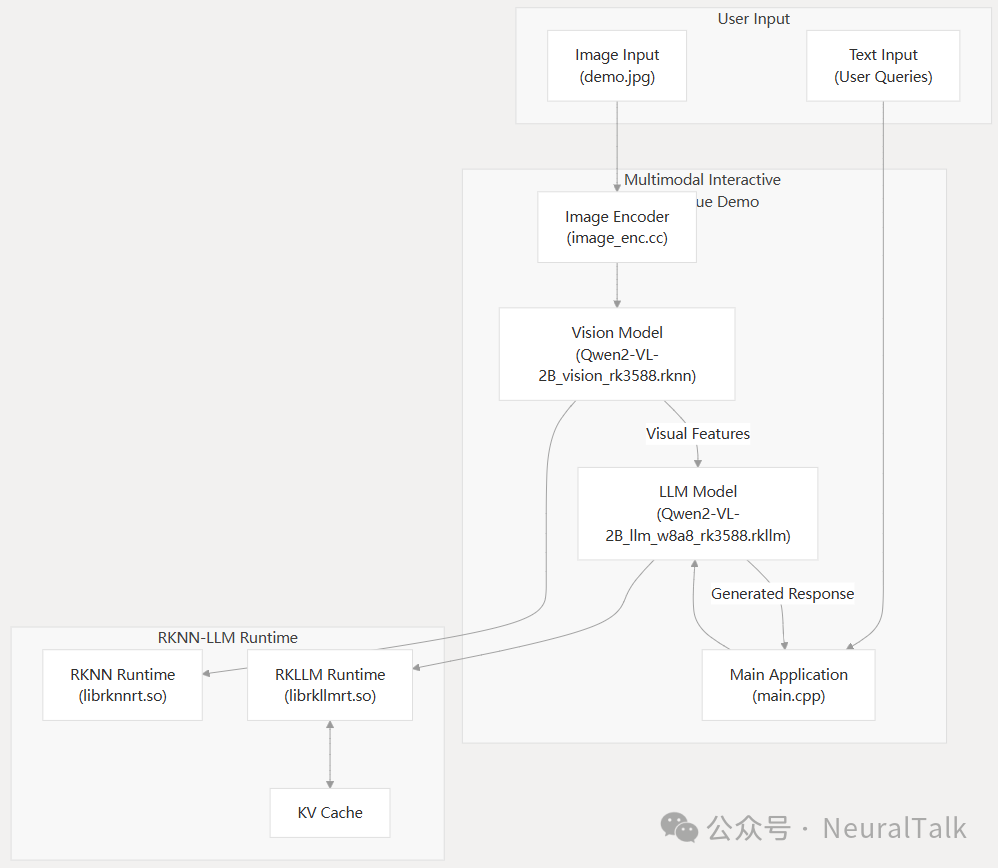
1. 图像视觉编码器(Vision Encoder)
模型选择:采用 qwen2_5_vl_3b_vision_rk3576.rknn 模型(本文)。 核心作用:将输入图像压缩为视觉 token 如 256 个视觉 token,直接输入至大语言模型中,实现图像信息向语言模型可理解格式的转换。
2. 大语言模型(LLM Core)
模型选择:搭载 qwen2.5-vl-3b-w4a16_level1_rk3576.rkllm 模型,采用 W4A16 量化方案(本文)。 模型规模:参数规模达 30 亿,KV-Cache,为对话推理提供核心的语言理解与生成能力。
3. 对话管家(Dialogue Manager)
基于纯 C++实现,采用单线程事件循环机制,承担着对话流程的统筹调度工作,具体职责包括:
1.3 核心逻辑:多轮对话的处理流程
该方案的多模态多轮对话 demo,整体遵循“模型加载 → 图片预处理 → 用户交互 → 推理输出”的核心流程,支持图文一体的多模态对话,适配多轮问答、视觉问答等典型场景。
具体运行机制可拆解为以下步骤:
1. 模型初始化
首先加载大语言模型(LLM),并配置模型路径、max_new_tokens(生成内容最大 token 数)、max_context_len(最大上下文长度)、top_k、特殊 token 等关键参数;随后加载视觉编码模型(imgenc),为后续图片处理做好准备。
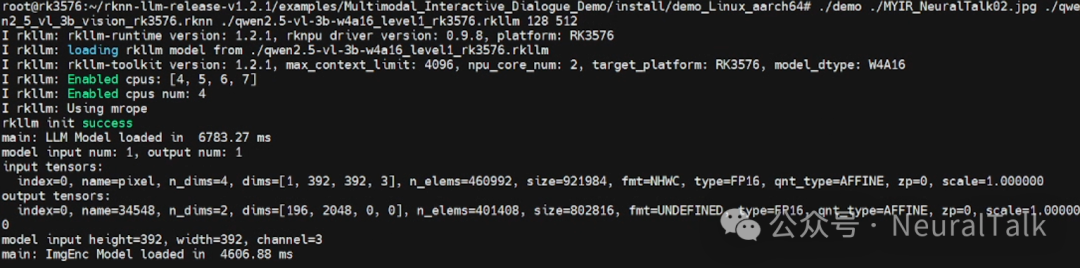
2. 图片处理与特征提取
读取输入图片后,先将其扩展为正方形并填充背景色以统一尺寸,再调整至模型要求的 392x392 分辨率,最后送入视觉编码模型进行处理,生成图片的 embedding 向量,完成图像特征的提取。
3. 多轮交互机制
程序会提供预设问题供用户选择(官方案例中也有输入序号,可以快速提问),同时支持用户自定义输入,核心交互逻辑通过以下机制实现:
rkllm_infer_params.keep_history = 1,开启上下文记忆功能,KV-Cache 在显存中持续追加存储,每轮对话仅计算新增 token,大幅提升推理效率。使模型能关联多轮对话内容;src/main.cpp。rkllm_clear_kv_cache(llmHandle, 1, nullptr, nullptr),清空模型的 KV 缓存,重置对话上下文。rkllm_set_chat_template()动态注入模型,无需重新训练即可切换人设,支持中英文双语系统提示。
模板示例如下:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
{用户输入}<|im_end|>
<|im_start|>assistant
4. 推理与输出
用户输入后,系统先判断输入中是否包含<image>标签:若包含,则将文本与图片 embedding 结合,启动多模态推理;若不包含,则进行纯文本推理。组装输入结构体并传递给模型后,推理结果将实时打印输出。
5. 退出与资源释放
支持用户输入“exit”退出程序,此时系统会自动销毁已加载的模型,并释放占用的硬件资源,确保运行环境的整洁。
二、工程化落地:从源码到部署的全流程
由于先前我们已经讲过环境的部署,如刷机、文件准备等,这里步骤只提出比较关键的。工程位于:rknn-llm/examples/Multimodal_Interactive_Dialogue_Demo,下面我们来逐步看下操作步骤。
2.1 依赖环境
方案的编译与运行需满足以下依赖条件
图像处理:OpenCV ≥ 4.5 视觉模型运行:RKNNRT ≥ 1.6 语言模型运行:RKLLMRT ≥ 0.9
2.2 一键编译
针对不同操作系统提供便捷的编译脚本,我们是 Linux 系统执行./build-linux.sh,编译结果如下:
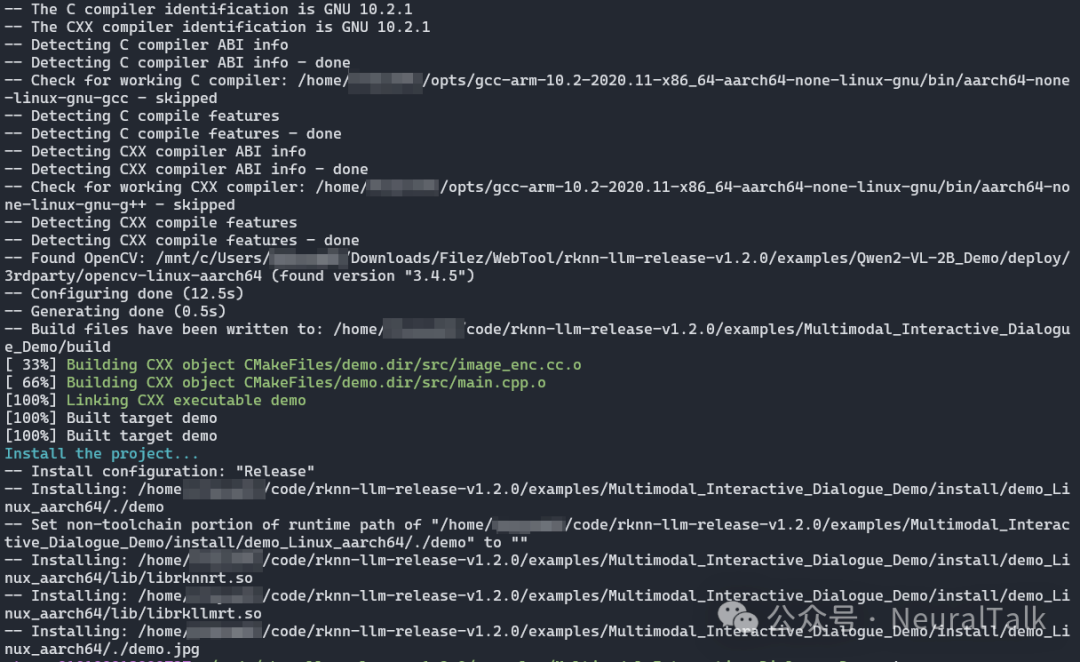
产物目录为:
install/demo_Linux_aarch64/
├─ demo # 主程序可执行文件
└─ lib # 依赖动态库
2.3 端侧部署步骤
通过 U 盘或者手机将编译好的产物文件、模型、图片上传到开发板上,然后在多轮对话的实例的目录下,执行以下命令:
cd /data/demo_Linux_aarch64
export LD_LIBRARY_PATH=./lib
./demo demo.jpg vision.rknn llm.rkllm 128 512
其中,部署命令需传入 5 个核心参数,分别对应:
image_path:输入图片路径encoder_model_path:视觉编码模型路径llm_model_path:大语言模型路径max_new_tokens:每轮生成的最大 token 数(控制回答长度,避免溢出)max_context_len:最大上下文长度(限制历史对话+当前输入总长度,防止显存占用过高)
三、效果展示:图文多轮问答
以下面这张图片作为测试图片,选择下面这张图是因为,有人物、文字、物体、背景等。

我们依次准备的问题如下:
每轮对话我都有截动态图,可以感受下体感速度。


可以明显感受到这两个过程是串行的,如果异步处理可以更快。
多轮对话1:这张图片上有哪些文字信息
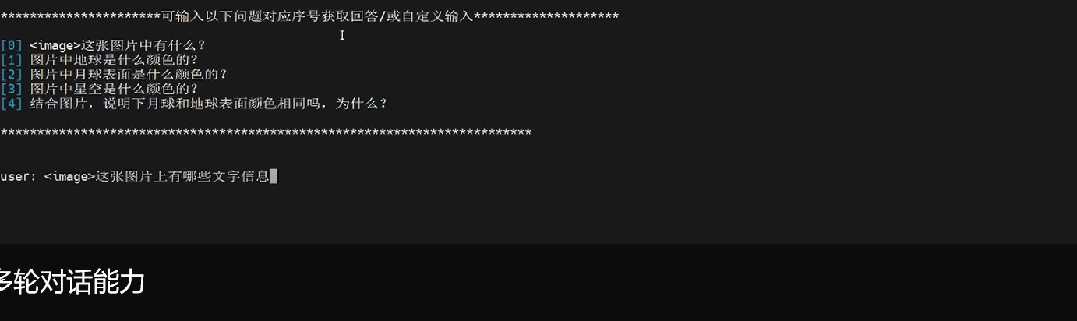

多轮对话2:图中电路板上的字是什么颜色

多轮对话3:图中女孩头发和衣服分别是什么颜色

多轮对话4:图中动漫角色看起来多大年龄


多轮对话5:图中背景颜色和女孩眼睛颜色一样嘛

rkllm_infer_params.keep_history = 1
代码中
keep_history = 1是开启上下文记忆功能,即模型应记住前序对话中的关键信息,如 “女孩眼睛颜色”“背景颜色”,而 “记不住” 是记忆功能未生效的表现,原因可能除了超过历史上下文预设的阈值,有时还有可能是因为上下文长度超限(max_context_len=512),或者KV-Cache 清理机制误触发等。
四、二次开发与拓展方向
方案具备良好的可扩展性,便于开发者根据需求进行二次开发:
image_enc.cc文件,将输入分辨率调整为与模型匹配的大小,原因是这些参数与模型的固有结构设计和输入处理逻辑强绑定,直接影响特征提取的正确性和数据传递的一致性。不同的 Qwen2-VL 模型(2B 和 7B)需要代码中指定IMAGE_HEIGHT、IMAGE_WIDTH及EMBED_SIZE;main.cpp中集成 VAD(语音活动检测)+ ASR(语音识别,如 Whisper-Tiny INT8)模块,将语音转换为文本后接入现有推理流水线,实现“看图说话+语音问答”的融合交互。
五、结论与未来发展方向
如果说 “大模型上云” 是 AI 的 “星辰大海”,那么 “多模态落地端侧” 就是 AI 的 “柴米油盐”—— 后者决定了智能技术能否真正渗透到智能家居、工业质检、穿戴设备等千万级场景中。RK3576 的多模态交互对话方案,其价值远不止 “实现了一项技术”,更在于提供了一套 “算力适配 - 工程封装 - 二次拓展” 的端侧 AI 落地范式。
从技术内核看,它通过 “视觉编码器 + LLM + 对话管家” 的模块化设计,平衡了推理性能与开发灵活性:W4A16 量化方案让 30 亿参数模型适配 6 TOPS 算力,KV-Cache 动态维护实现多轮对话效率跃升,单线程事件循环降低了资源占用 —— 这些细节不是技术炫技,而是直击端侧 “算力有限、场景碎片化” 的痛点。从工程落地看,一键编译脚本、清晰的参数配置、可复现的部署流程,让开发者无需深耕底层优化即可快速验证场景,大幅缩短了从技术原型到产品的周期。
展望未来,这套方案的演进将围绕三个方向深化:
当 RK3576 证明 “端侧能跑好转好多模态对话” 时,边缘 AI 的竞争已从 “能否实现” 转向 “如何更优”。而这套方案的真正意义,在于为行业提供了一块 “可复用的基石”—— 让更多开发者无需重复造轮子,只需聚焦场景创新,就能让 “离线智能” 从实验室走向量产货架,最终让 “AI 就在身边” 成为无需网络支撑的常态。
参考资料
airockchip/rknn-llm: 'https://github.com/airockchip/rknn-llm'



2026-01-22
看过来,米尔RK3576 NPU方案你用对了吗?
本文基于米尔MYD-LR3576开发板,详细记录了如何利用500万像素USB摄像头实现640×640分辨率的YOLO5s目标检测,并将结果实时输出至1080P屏幕的全流程。通过系统级的软硬件协同优化,最终将端到端延迟控制在40ms以内,实现了 20FPS的稳定实时检测性能。文章重点剖析了摄像头特性分析、显示通路选择、RGA硬件加速、RKNN NPU集成等关键技术环节,为嵌入式AI视觉系统的开发与调
2026-01-22
全场景工控与网关解决方案:从入门到旗舰的一站式选型
在工业自动化与物联网向深度智能迈进的浪潮中,工业设备对成本控制、运行可靠性及智能算力的要求正持续攀升。无论是追求极致性价比的基础工控终端,还是需要强劲算力支撑的AIoT边缘节点,开发者都在为不同场景寻觅适配的“工业之芯”。对此,我们基于MYC-YR3506、MYC-LT536、MYC-LR3576三款核心板,打造了覆盖低、中、高端全场景的工业控制与网关解决方案,以一站式选型体系,助力工业产品实现“
2026-01-15
当国产芯遇上机器人:RK3576的ROS2奇幻之旅
当RK3576的强劲“大脑”(四核A72+四核A53)与强大的GPU、VPU、NPU加速模块相遇,一场高性价比的机器人开发革命正在悄然发生。我们成功将完整的Ubuntu 22.04与ROS2 Humble生态系统,完美移植到了这颗国产芯片上。一个稳定、全功能的机器人软件开发平台已经就绪,现在就来一起探索它的强大魅力!一、系统启动与基础性能展示1.硬件平台简介开发板:MYD-LR3576存储:eMM
2026-01-15
内置全栈安全,一站式满足CRA法案与IEC 62443标准-米尔MYC-LF25X核心板
面对日益严峻的网络安全挑战,欧盟《网络弹性法案》(CRA)的出台与工业安全标准IEC 62443的广泛应用,为设备制造商筑起了新的合规门槛。安全不再是可选功能,而是产品设计的强制基石。米尔电子推出的MYC-LF25X嵌入式处理器模组,基于已通过SESIP 3级认证的意法半导体STM32MP257F处理器,提供从硬件信任根到应用层的全栈、可验证安全架构,是您高效开发符合国际法规与标准的安全关键型应用
2025-12-26
补贴太香了!158元买米尔NXP i.MX 91开发板,限购300套
太香了!限时补贴狂欢,回馈您的支持!米尔基于NXP i.MX 91开发板仅158元,限量300套,先到先得。该开发板基于新一代NXP i.MX 91系列处理器设计,搭载Arm Cortex-A55核心,集成双千兆以太网和双 USB 端口等丰富外设,支持Linux、Android等主流操作系统,赋能新一代入门级Linux应用,适用于工业控制、智能终端、物联网等领域的原型开发与教学实践。产品型号:MY
2025-12-19
Buildroot MQTT-Modbus 网关开发,实现设备远程监控方案-米尔RK3506
在工业物联网与智能家居场景中,远程设备监控的核心痛点是工业总线协议与物联网协议的兼容性问题。基于RK3506 Buildroot系统开发的MQTT-Modbus网关产品,通过协议桥接技术完美解决这一难题,为低成本、高可靠的远程监控提供了高效解决方案。一、核心开发平台与技术选型硬件平台选用RK3506处理器作为网关核心硬件,该芯片具备低功耗、高性价比特性,支持多接口扩展,完全适配工业级嵌入式场景需求
2025-12-19
SDK重磅升级,RK3506核心板解锁三核A7实时控制新架构
在工业控制与边缘智能领域,开发者的核心需求始终明确:在可控的成本内,实现可靠的实时响应、稳定的通信与高效的开发部署。米尔电子基于RK3506处理器打造的MYC-YR3506核心板平台,近期完成了一次以“实时性”和“可用性”为核心的SDK战略升级,致力于将多核架构的潜力转化为工程师可快速落地的产品力。本次升级围绕两大主线展开:系统生态的多样化与实时能力的深度释放。我们不仅提供了从轻量到丰富的操作系统
2025-12-11
赋能欧标充电桩市场:OCPP协议实战开发指南
随着全球电动汽车产业的迅猛发展,充电基础设施的智能化与标准化已成为行业迫切需求。OCPP(Open Charge Point Protocol即开放充电点协议)作为连接充电桩与中央管理系统的"通用语言",正成为解决设备互联互通难题的关键技术。一、OCPP:为何是出海欧标的必选项?OCPP是一个开放、标准的通信协议,它确保了不同制造商生产的充电桩能够与任何兼容的后台管理系统进行无
2025-12-11
打造本地化智能的“最强大脑”, 米尔RK3576 AI边缘计算盒
在人工智能与边缘计算深度融合的浪潮中,本地化智能需求正重塑产业格局。米尔电子推出的RK3576边缘计算盒,具备高算力、低功耗与强扩展性,凭借其卓越的硬件架构与多场景适配能力,正成为推动工业视觉、工程机械及智慧城市等领域智能化产业升级的有力工具。米尔MYD-LR3576-B边缘计算盒基于瑞芯微中高端RK3576芯片,采用异构计算架构,集成4核Cortex-A72与4核Cortex-A53处理器,搭配
2025-12-05
从两轮车仪表到工程机械环视,米尔用国产芯打造“越级”显控体验
在工业4.0 与智能化浪潮的推动下,传统工业设备正在经历一场“交互革命”。从电动两轮车的智能仪表,到工程机械的 360° 环视中控,用户对“更高清的显示、更流畅的触控、更丰富的互联”提出了严苛要求。然而,面对复杂的工业现场,开发者往往面临两难:低端市场(如仪表、充电桩):传统MCU 跑不动复杂界面,上 Linux/安卓方案成本又太高。中高端市场(如工程机械、医疗):多路视频输入(如360环视)需要